SectorScan: Comparing stock sector performance in Indonesia
We will build a financial analytics app, called SectorScan, that turns data from different sectors into beautiful, easy-to-understand visualizations. User can choose which sectors to compare, and the app will analyze the Market Cap, Valuation, and Top Companies in those sectors. By comparing various sectors, user can quickly spot which ones are performing better than the others. It’s like having a bird’s eye view of the market, making it easier to see trends and patterns that might not be obvious otherwise. This app is great for investors who want to track the market without getting lost in the details.The tools: streamlit and altair
The entire app will be built using streamlit, an open-source Python app framework that’s incredibly easy to use and perfect for beginners. With streamlit, you can create beautiful, interactive web applications with just a few lines of Python code. It’s designed to let you focus on your data and insights without needing extensive web development experience, making it ideal for data scientists, analysts, and developers.
For the visualizations, we’ll use altair, a powerful and user-friendly Python library. altair works seamlessly with streamlit, allowing you to create stunning, interactive charts and graphs. Even if you’re new to Python, the simplicity of streamlit combined with the intuitive design of altair will help you get started quickly. Rest assured, you’ll get along just fine with this recipe!
Note: If you want to first get familiar with altair, you can self-enroll in the Data Visualization with Altair course offered by Supertype Fellowship.
Prerequisite
To follow this recipe, you need the following prerequisites:- Python installed on your machine
- Visual Studio Code or an IDE of your choice
- Valid API keys from Sectors Financial API, which you can acquire from your Sectors App account
- The pip management tool
-
streamlit v.1.35.0package installed, by running the following code:By installing this package, all the necessary dependencies, includingpandas,requests, andaltair, will also be installed.
Dive into the data
In this section, we’ll dive into exploring and visualizing data from the Sectors Financial API, setting the foundation for our app. Feel free to use Google Colab or create a.ipynb notebook in your IDE to follow along and experiment with the data. We’ll start by getting familiar with the data and creating some insightful visualizations.
Alright, first things first. Please make sure you already have your API key from your Sectors App. And since we’ll be calling some endpoints from the Sectors Financial API, let’s create a simple function to handle this. This will make our next steps much easier:
List of All Sectors
Before we can compare data from different sectors, we need to get a list of all available sectors. This can be achieved by using the following endpoint from the Sectors Financial API:sectors.
subsector data to filter our data later on, we’ll create a list contains of the subsector data only:
Market cap
As I mentioned before, there are three things that we want to compare in SectorScan, and the first thing is Market Cap.Market cap data processing
We can utilize the following endpoint to get the market cap data from each sector:total_market_cap, quarterly_market_cap, and monthly_performance into three pandas data frames:
-
mc_currto store the total market cap:The result:Sector Total Market Cap 0 Financing Service 4.676535e+13 -
mc_histto store the quarterly market cap: First let’s test how the data frame would look like if we try to create one fromquarterly_market_cap:The result:To make it easier to be visualized, we will change the data format from2022.Q2 2022.Q3 2022.Q4 2023.Q1 quarter 39870000000000 41848000000000 43047000000000 49290000000000 widetolongusingpd.melt()function, then add theSectorcolumn:The result:Since there are two keys inSector Quarter Market Cap 0 Financing Service 2022.Q2 39870000000000 1 Financing Service 2022.Q3 41848000000000 2 Financing Service 2022.Q4 43047000000000 3 Financing Service 2023.Q1 49290000000000 quarterly_market_capthat we want to use:prev_ttm_mcapandcurrent_ttm_mcap, we can use looping to create the finalmc_hist:pd.concat()there is working to combine the data frame ofprev_ttm_mcapandcurrent_ttm_mcapinto one data frame. -
mc_changeto store the monthly performance Similar asmc_hist, we will usepd.melt()to create an easier-to-be-visualized data frame:The result:Sector Date Market Cap Change 0 Financing Service 2023-06-30 1.601451e-01 1 Financing Service 2023-07-31 -7.817735e-04 2 Financing Service 2023-08-31 -7.589136e-02 … … … …
Total market cap visualization
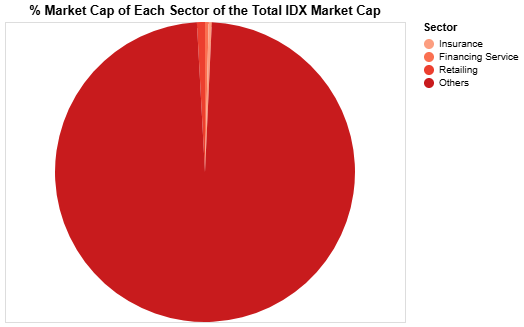
In this first visualization, we want to compare the total market cap of each sector. But to make the visualization more robust, we will compare the percentage market cap of each sector from the total IDX market cap. Thus, we will need to first combine ourdf_mc_curr with the IDX market cap data that we can obtain using the following endpoint:
idx_mc:
df_mc_curr to meet our needs for the visualization:
| Sector | Total Market Cap | % Market Cap | Market Cap (Trillion IDR) | |
|---|---|---|---|---|
| 0 | Financing Service | 4.676535e+13 | 0.381127 | 46.765350 |
| 1 | Insurance | 3.975552e+13 | 0.323999 | 39.755524 |
| 2 | Retailing | 1.141295e+14 | 0.930130 | 114.129518 |
| 3 | Others | 1.206962e+16 | 98.364744 | 12069.621623 |
altair to do it:
alt.Chart() function initializes the chart, .mark_arc() defines that the chart should use arcs to represent the data, .encode() maps the data columns to visual properties of the chart including the theta (% Market Cap), color (Sector), & tooltip (Sector, % Market Cap, Market Cap (Trillion IDR)) and .properties() sets additional properties of the chart including the title and width.
Notice that I use :Q and :N behind the column names, these are used to specify the data type, with Q stands for quantitative, and N stands for nominal.
You should have a pie chart looks like the followings:
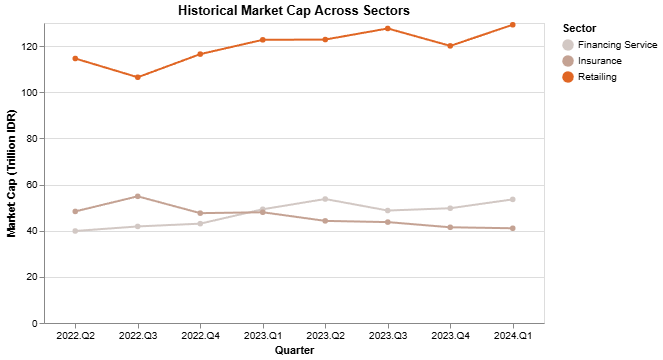
Historical market cap visualization
Now let’s create our next visualization, which will show the historical market cap that we have stored indf_mc_hist. We only need to slightly modify the data frame to include the market cap in trillion IDR, using the following code:
| Sector | Quarter | Market Cap | Market Cap (Trillion IDR) | |
|---|---|---|---|---|
| 0 | Financing Service | 2022.Q2 | 39870000000000 | 39.870 |
| 1 | Financing Service | 2022.Q3 | 41848000000000 | 41.848 |
| 2 | Financing Service | 2022.Q4 | 43047000000000 | 43.047 |
| … | … | … | … | … |
.mark_line():
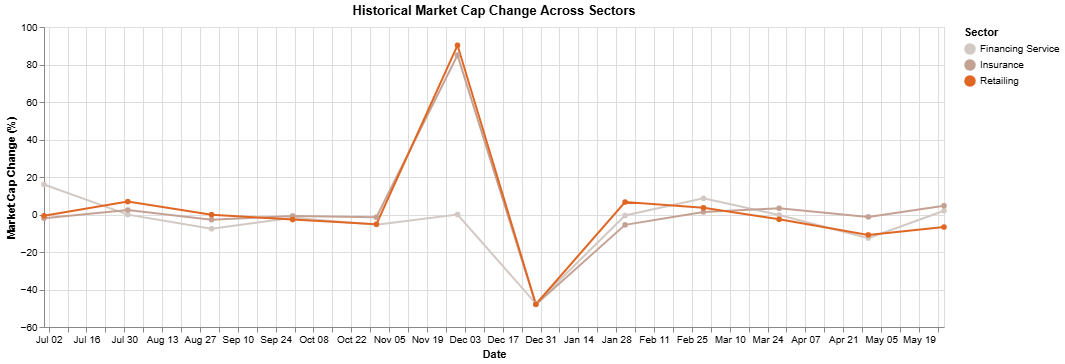
Historical market cap change visualization
Our last market cap visualization is to show the historical market cap change that we have stored indf_mc_change. Let’s first change the format of the change from decimal to percentage:
| Sector | Date | Market Cap Change | Market Cap Change (%) | |
|---|---|---|---|---|
| 0 | Financing Service | 2023-06-30 | 1.601451e-01 | 1.601451e+01 |
| 1 | Financing Service | 2023-07-31 | -7.817735e-04 | -7.817735e-02 |
| 2 | Financing Service | 2023-08-31 | -7.589136e-02 | -7.589136e+00 |
| … | … | … | … | … |
df_mc_hist we’ll use line chart to visualize it:
Valuation
Now let’s move on to the Valuation. There are four valuation metrics that we’ll try to compare:- Price/Book Ratio
- Price/Earning Ratio
- Price/Sales Ratio
- Price/Cash Flow Ratio
Valuation data processing
The valuation data can be obtained using the following endpoint:historical_valuation into pandas data frame using the following function,
| Price/Book Ratio | Price/Earning Ratio | Price/Sales Ratio | Price/Cash Flow Ratio | Year | Sector | |
|---|---|---|---|---|---|---|
| 0 | 1.128118 | 15.226366 | 3.407392 | 1.866339 | 2020 | Financing Service |
| 1 | 1.708792 | 15.256327 | 5.972283 | 2.288791 | 2021 | Financing Service |
| 2 | 1.322785 | 11.479534 | 5.640499 | -4.803930 | 2022 | Financing Service |
| … | … | … | … | … | … | … |
Valuation visualization
Now since the data is ready, let’s visualize it. We’ll compare the Price/Book Ratio of the sectors using a line chart: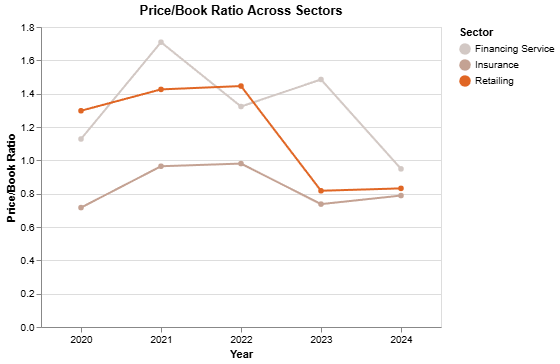
Price/Book Ratio in the code above with the metric: Price/Earning Ratio, Price/Sales Ratio, or Price/Cash Flow Ratio, and you should get a similar visualization as above but with the chosen metric value.
Top companies
The last aspect we’ll compare between the sectors is the Top Companies. For this comparison, we’ll use four criteria to identify the top companies in each sector:- Top companies based on Market Cap
- Top companies based on Revenue Growth
- Top companies based on Profit
- Top companies based on Revenue
Top companies data processing
Data for the top companies can be retrieved using the following endpoint:top_companies key into four different data frames:
Top companies based on market cap visualization
We just need to slightly modify thedf_top_mc before it’s ready to be visualized:
.mark_bar()) to visualize the df_top_mc:
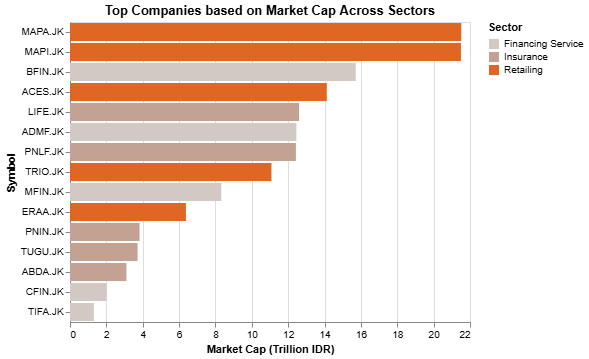
Top companies based on revenue growth visualization
Slightly change the revenue growth from decimal to percentage: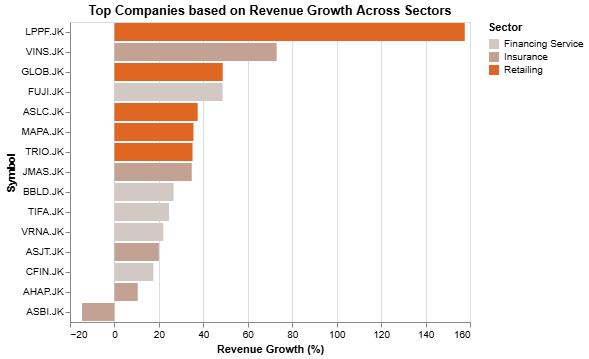
Top companies based on profit visualization
For profit, we want to change the unit of measurement from IDR to Billion IDR: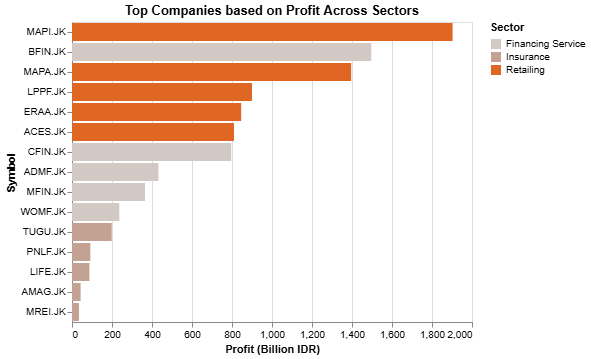
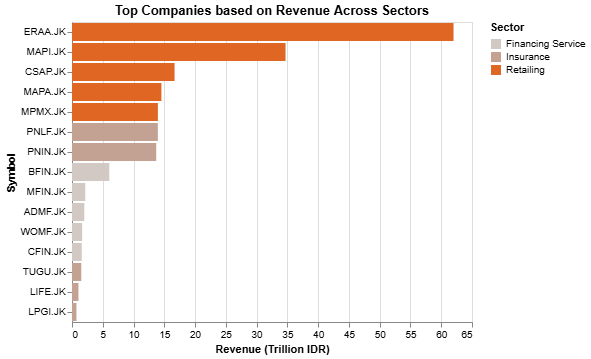
Top companies based on revenue visualization
Last one, we’ll first add new column for the revenue in trillion IDR using the following code: